Rust vs Go: Better Together
While others may see Rust and Go as competitive programming languages, neither the Rust nor the …
I build tools that make developers’ lives better.
I create open source projects including Hugo and Cobra that have earned over 185K+ GitHub stars.
I’ve shaped the modern developer stack: from architecting MongoDB’s user experience and scaling Go at Google, to pioneering container standards at Docker and driving AI at Two Sigma.
Here, I write about the human stack and the art of building products and teams that last.
While others may see Rust and Go as competitive programming languages, neither the Rust nor the …
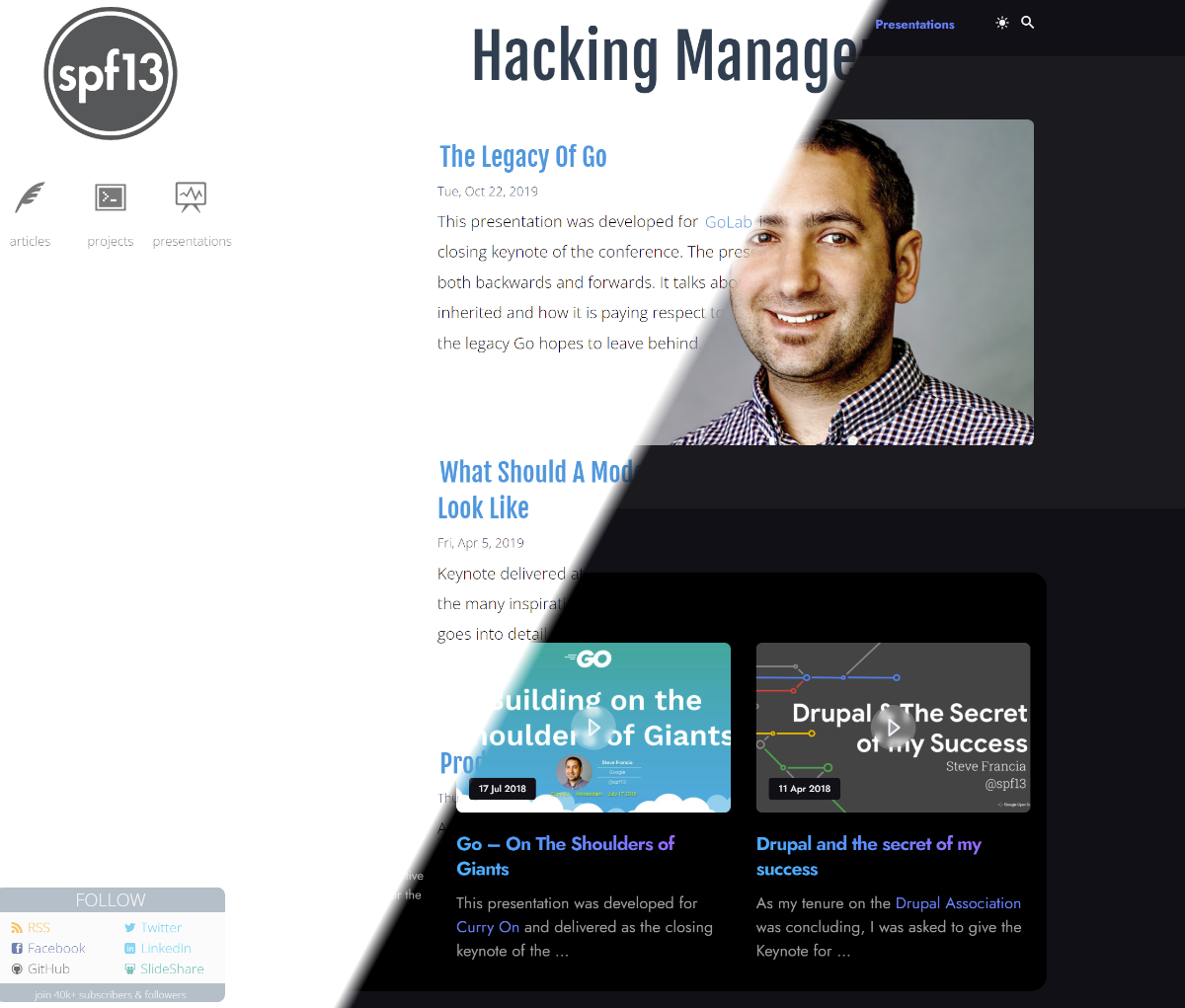
This presentation was developed for Curry On and delivered as the closing keynote of the …
As my tenure on the Drupal Association was concluding, I was asked to give the Keynote for …
A comprehensive framework for evaluating the total, long-term economic impact of programming language choices across nine critical cost dimensions.
The neuroscience of why we make million dollar decisions based on identity, not data.
Benjamin Franklin discovered gradient descent 250 years before we had the mathematics to describe it.
When foundational open source projects like Cobra and Viper level up their security game, the entire ecosystem wins. Here's what we learned together.
I’m leaving my role as the Product Lead for the Go Language at Google. I’m super proud of …
I’m proud to present the new and improved spf13.com a dramatic redesign of the very first …
I had the pleasure of speaking with Olimpiu Pop from InfoQ about the Go language and community. …
Go Time panelists Natalie & Jon join forces with Go Team members Steve Francia, Katie …
Go, the language of cloud infrastructure, is maturing into the language of modern enterprise …
Over the past couple of years, Go has matured to a complete end-to-end offering with seamless …
The folks at Develer liked JT’s and my article Rust vs Go - Better together so much they …
While others may see Rust and Go as competitive programming languages, neither the Rust nor the …
I had the privilage of sitting down with my friend Jason Yee as a guest on his podcast. Listen …
I had the privilage of joining my coworker Julie Qiu as we talked with our friends Carmen, Mat …
This presentation was developed for GoLab in Firenze Italy and delivered as the closing keynote …
I was traveling with my son in Utah, visiting my old university and connected with our Go Users …
Keynote delivered at The Landing Festival – Berlin. This presentation describes the many …
An interactive workshop developed for and given at the Landing Festival in Berlin 2019. This …